前言
EfficientDet论文自去年放到arXiv上就备受人们关注,但一直没人能复现它的结果,直到3月份release代码,才让人们知道其中实现的细节。我在复现EfficientDet的过程中可以说是踩坑无数,看了官方release的代码,才发现里面充满了炼丹的技巧…
EfficientDet的结构与RetinaNet类似,都分为backbone、neck和head三部分。EfficientDet的backbone为EfficientNet系列,neck为论文中提出的bifpn,head与RetinaNet一样(此处有坑…)。根据网络规模的不同,衍生出D0~D7的8种不同精度的结构,其中D7达到了SOTA的水平。下面就说下我在复现过程中遇到的坑。
踩过的坑
Backbone
- 论文中从EfficientNet中取了P3~P7的5个scale的feature map作为BiFPN的输入,但是EfficientNet只有1/8~1/32的三个scale。github上最早的EfficientDet复现代码采用了魔改EfficientNet的方式,将其中两个block的stride改为了2。这么做显然很不靠谱,我只好采用了RetinaNet中的方式,通过Downsample来得到1/64和1/128的feature map。后来证明官方确实也是这么做的,只是可能是为了减少计算量,官方中用的max_pooling做的降采样,而我当初用的是3x3conv。
- BN是否更新的问题。在检测任务中,有时会freeze backbone中BN,而我实验时发现EfficientDet不固定BN比固定BN要高2个点。后来看官方代码也是这么做的。
BiFPN
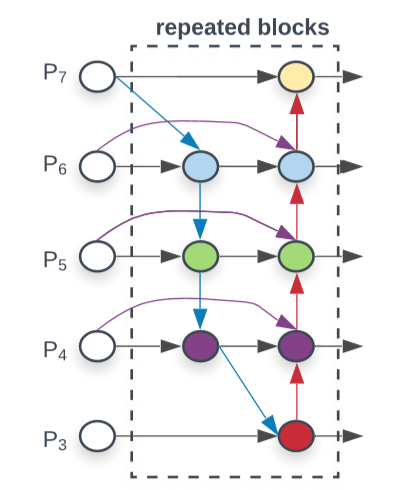
上图就是BiFPN的最小结构,看起来不是很复杂,实际上充满了细节。
- 没有lateral_conv。一般在FPN中会通过lateral_conv来对齐backbone输出与fpn输入的channel数,但EfficientDet中没这样做。
- 在第一层BiFPN中P5和P4节点的两个输出为不同tensor(图中根本看不出来~)。在官方代码中,上图中的彩色节点的输入都会经过Resample的过程,而Resample会在输入channel数与输出channel数不等时添加1x1conv,所以就导致了第一层BiFPN中P5和P4节点的两个输出为不同tensor。
- 在第一版论文中只提到了上图的彩色节点由separable conv BN与activation组成,没有说三者的顺序以及是哪种activation。这点在最新论文中有提及,每个彩色节点由swish-BN-sepconv组成。
Head
head中的坑并不多,主要是它把正常RetinaHead中的conv都换成了separable conv,以及在不同level间只共享conv的参数,不共享BN的参数。
训练过程
- 在第一版论文中有一个关键的训练参数没有提及,就是epoch。当初复现时,通过论文图片猜测他训了120epoch左右,结果它足足训了300epoch…
- 另一个坑是关于数据预处理的,第一版论文中没有提及使用了random crop,使用random crop会比不使用提升3个点左右。
复现结果
最后贴上我的复现结果,在参考了官方release的代码后,EfficientDet-D0终于复现到接近论文的精度了,不容易啊~
| mAP(val2017) | Params | FLOPs | mAP(val2017) in paper | Params in paper | Flops in paper | |
|---|---|---|---|---|---|---|
| D0 | 32.02 | 3.87M | 2.55B | 33.5 | 3.9M | 2.5B |
代码在https://github.com/lucifer443/EfficientDet-Pytorch,欢迎star。