
一、简介
同EfficientDet一样,这也是一篇CVPR2020做目标检测的paper,但与EfficientDet不同的是,它采用了NAS的方法设计网络。SpineNet-190在COCO上的mAP达到了52.1%,是现在的SOTA。
动机
经典的CNN都会进行多次降采样,这种结构并不适合目标检测等需要位置信息的任务。所以detection网络中通常会采用encoder-decoder的结构来获得不同尺度的特征(encoder即resnet等backbone网络,decoder即FPN等特征融合网络)。作者想探究的就是这种做法的必要性。如果一个网络既能学到特征信息又能位置信息,就可以直接将muti-level的feature传给detector。
思路
位置信息的损失来自于CNN持续的downsample,所以一个直观的想法就是在CNN中不使用这种down sample的结构。那应该采用怎么样的结构呢?作者通过NAS来解决这个问题。
二、方法
为了限定搜索空间,作者以经典的ResNet为起点,通过NAS的方式搜索了各个Block的排列与连接方式,从而得到了一个新的网络,称为scale-permuted backbone。
Search Space
-
Scale permutations:各个block的排序,总共N个block,其中N-5个intermediate block, 5个output block用于得到最终的muti-level feature,搜索空间为(N-5)!5!
-
Cross-scale connections:每个block最多有两个输入,这些输入来自其父block中的任意一个,搜索空间为 \(\prod_{i=0}^{n-1}{C_2^i}\\\)
-
Block adjustments:每个Block的调整,分为level和type两个方面,对于intermediate block,它的level的变化可以从{−1,0,1,2}选,搜索空间为$4^{N-5}$。对于所有block,type可以从{bottleneck block, residual block},搜索空间为$2^N$。
Resampling in Cross-scale Connections
由于不同level的block的feature map尺寸是不一样的,所以在连接不同level的block时,需要引入resample操作,具体如下图所示。对于从小到大的操作,由最近邻上采样完成;对于从大到小的操作,由3x3 Conv以及maxpool完成。在重采样前后都有1x1操作,用于控制计算量和对齐输入channel数。
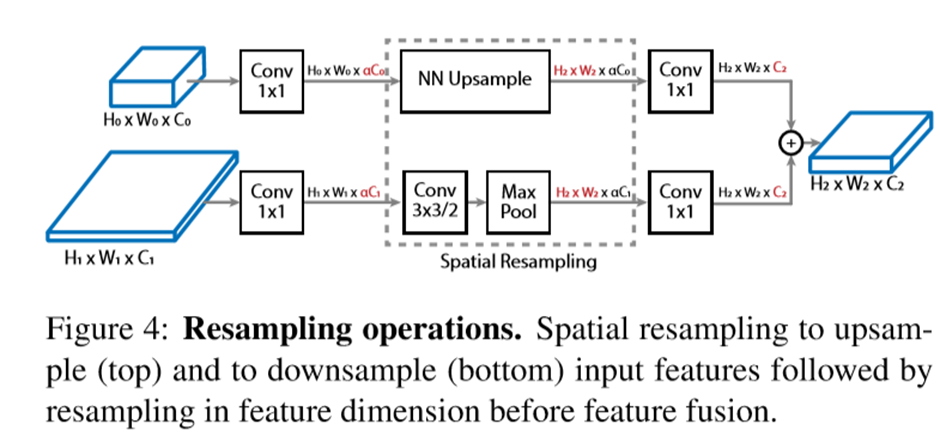
SpineNet Architectures
SpineNet最终搜出的结构如下图所示,可以看到,相比原始的R50-FPN(RetinaNet)提高了3个点。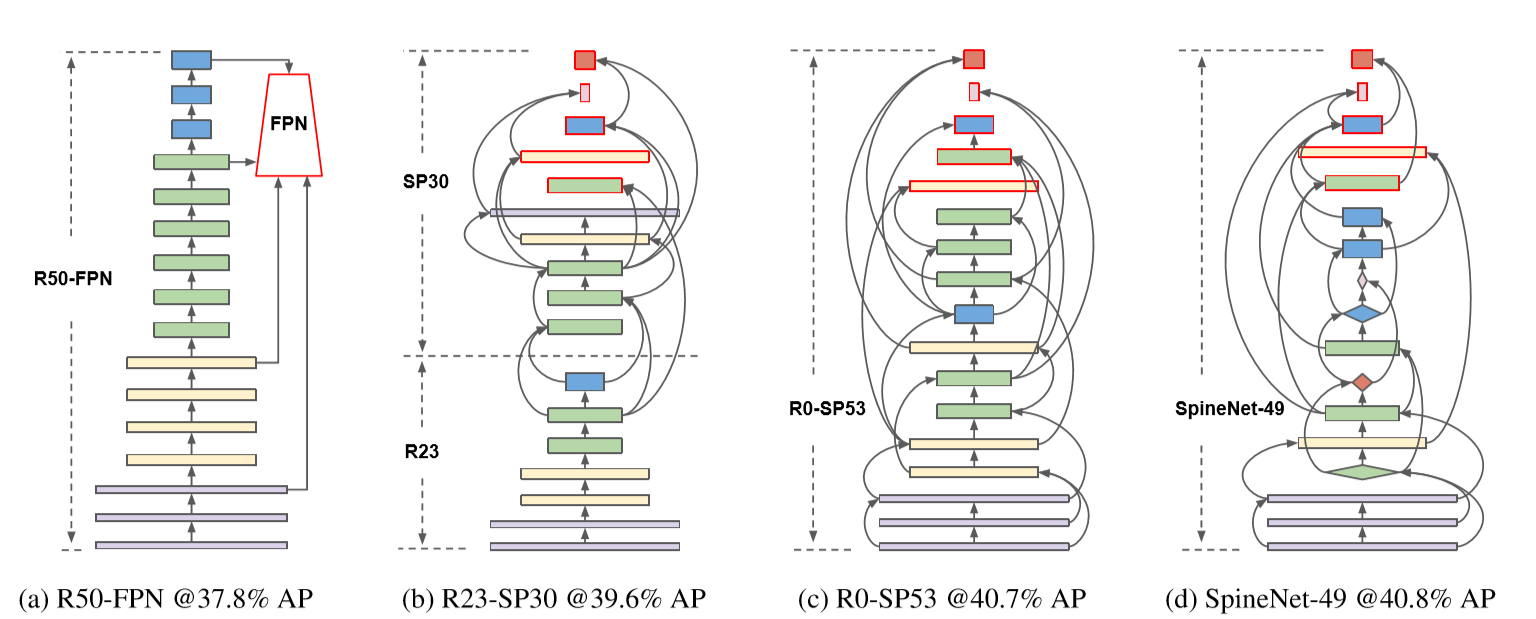
作者以搜出的SpineNet-49为基础,通过缩小channel(SpineNet-49S)或拓展block数(SpineNet-96/143)的方式,得到了SpineNet-49S/49/96/143等一系列不同规模的网络。
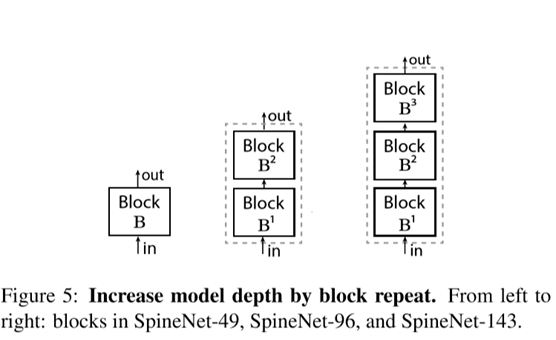
四、实验设置
Training Details
论文中采用3中不同的训练策略,不同策略得到的精度不同,protocol C训出的网络精度最高,SpineNet-49可以训到44.3%mAP:
- protocol A: random scale between[0.8,1.2];250 epochs;DropBlock
- protocol B: random scale between[0.5,2.0];350 epochs
- protocol C: random scale between[0.5,2.0];500 epochs;stochastic depth;Swish
NAS Details
- reinforcement learning to train a controller to generate model architectures
- proxy SpineNet
- restrict intermediate blocks to search for parent blocks within the last 5 blocks built and allow output blocks to search from all existing blocks.
五、实验结果
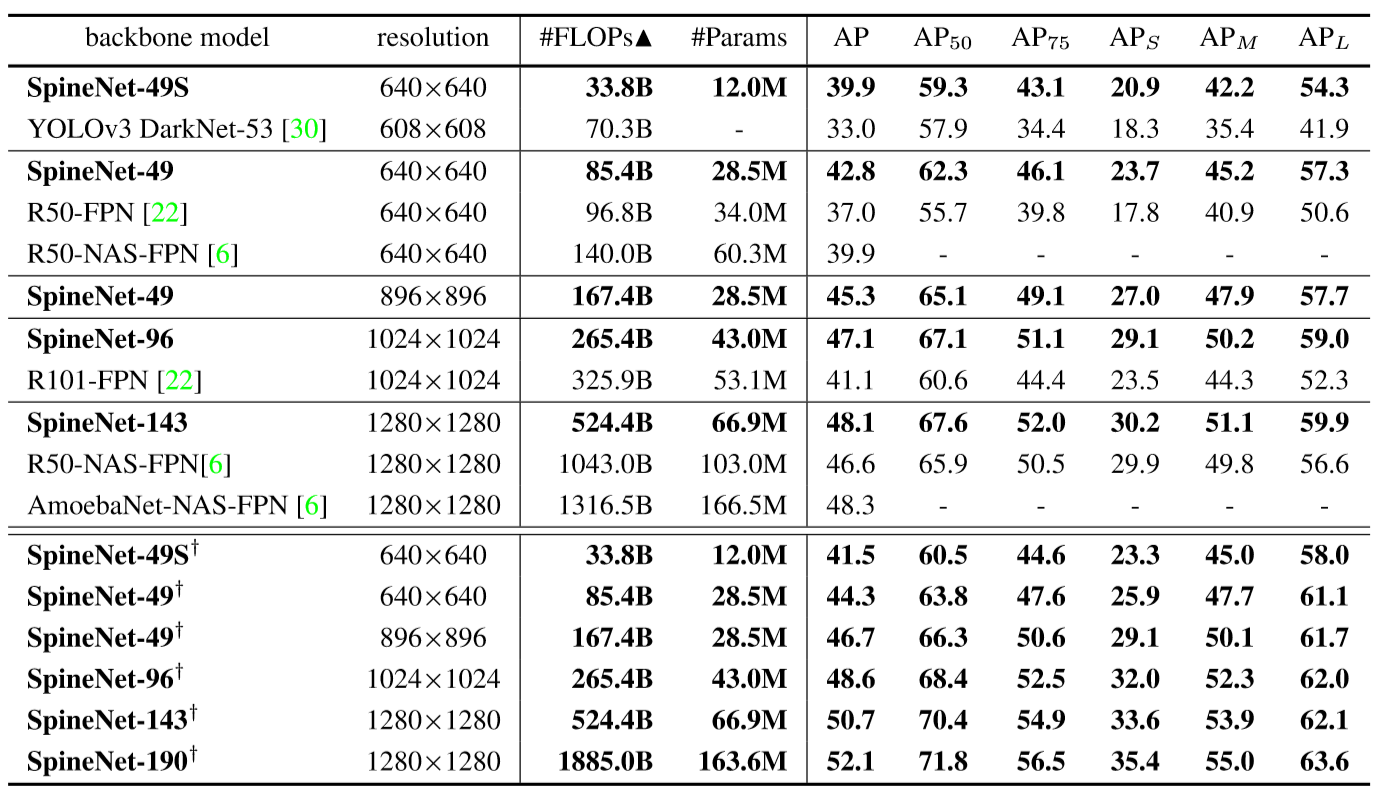
实验结果如下表所示,可以看到最优结果(SpineNet-190)比EfficientDet-d7还高一点。
六、总结
- 个人感觉这篇文章的思路出发点还是有点意思。
- SpineNet整个网络只有ResNet Block,相比EfficientDet在GPU上会更加高效,精度也不差。
- 从训练角度看,SpineNet是train from scratch的,从作者的实验中也可以看出,R50-FPN这样训得到的精度更高。这说明pretrain model在大数据集上是不必要的。
- 刚看第一版论文时,被论文中的结果有点吓到了。。。第一版对比R50-FPN和SpineNet时,没有使用一样的训练策略,R50-FPN mAP 37%而SpineNet mAP 42.7%,让人以为提升了5.7个点。这也说明作者找的这组超参比较好,可以学习下。
代码
- TensorFlow(official):https://github.com/tensorflow/tpu/tree/master/models/official/detection
- Pytorch(我复现的,SpineNet-49 mAP 42.7%):https://github.com/lucifer443/SpineNet-Pytorch